



- Impact
- 27,421
Having relatives and friends scattered all over the globe, I am getting an overload of input (some on the record and some off the record).
My intention for this thread is for community members from around the world to post first hand stories and/or links to information sources that, for the most part, should be reliable.
In my community, just outside a major southeastern city, 'assets' have been placed. Only because I have friends in both high and low places have I heard about some of this. At this point it is only some basic medical supplies that should be equally distributed anyway in preparation for a natural emergency (hurricane/wildfire/etc.).
I will start with posting a link to a site with current data that seems to come from an aggregate of sources and hope others will do the same as they come across similar sites/pages.
Because of the 'typhoid Mary' spread-ability of this disease, I feel we may be in for a really large spread globally which will impact the global economy and through extension, retail domain prices.
One thing is for sure...things will get worse before they get better.
https://www.worldometers.info/coronavirus/usa-coronavirus/
My intention for this thread is for community members from around the world to post first hand stories and/or links to information sources that, for the most part, should be reliable.
In my community, just outside a major southeastern city, 'assets' have been placed. Only because I have friends in both high and low places have I heard about some of this. At this point it is only some basic medical supplies that should be equally distributed anyway in preparation for a natural emergency (hurricane/wildfire/etc.).
I will start with posting a link to a site with current data that seems to come from an aggregate of sources and hope others will do the same as they come across similar sites/pages.
Because of the 'typhoid Mary' spread-ability of this disease, I feel we may be in for a really large spread globally which will impact the global economy and through extension, retail domain prices.
One thing is for sure...things will get worse before they get better.
https://www.worldometers.info/coronavirus/usa-coronavirus/
Last edited:

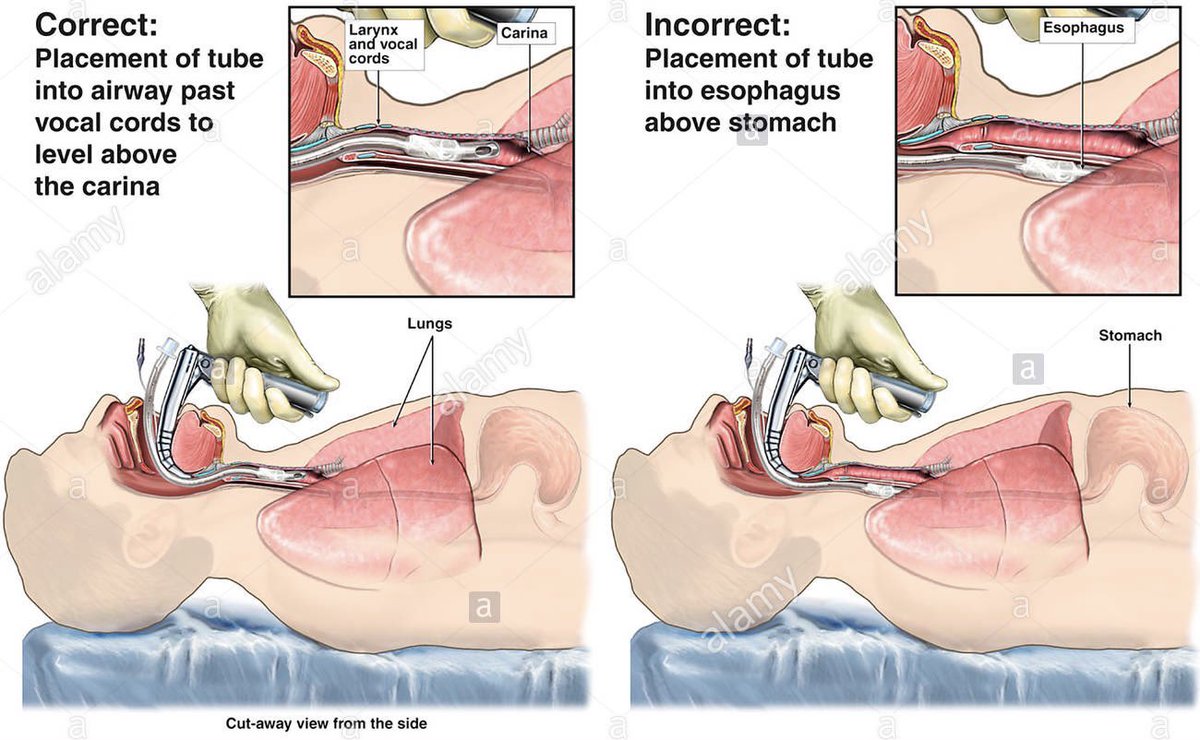
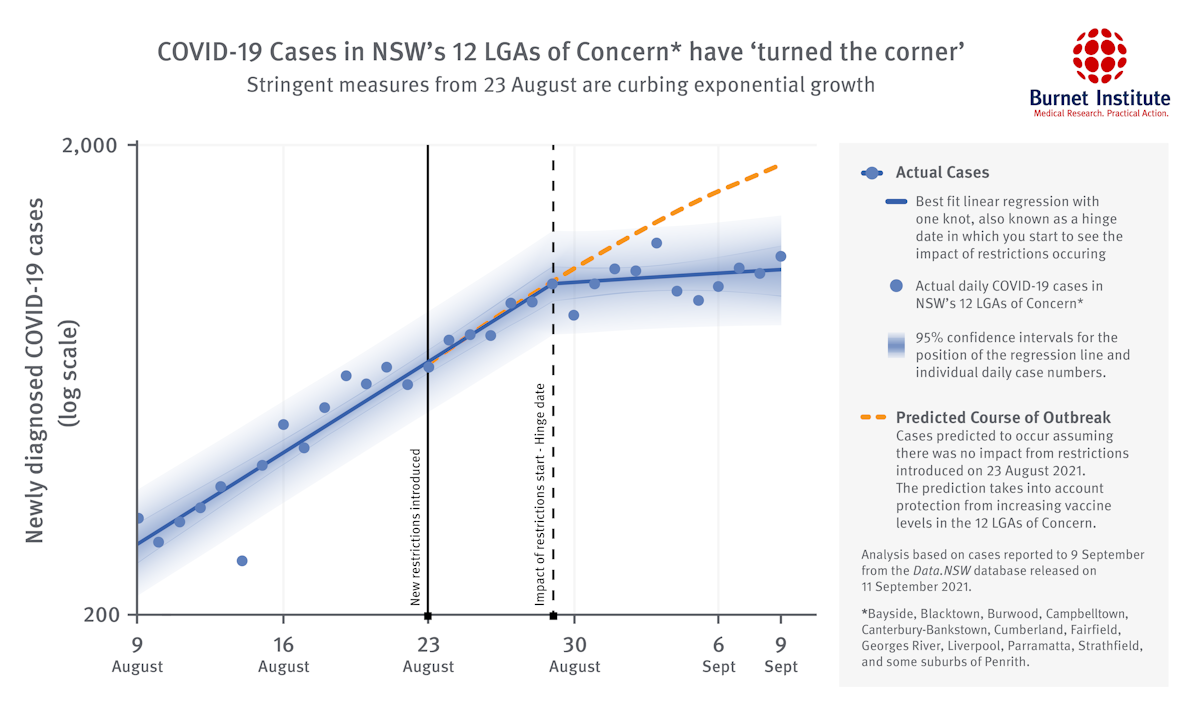
 “
“

